2 Metadata
2.1 Introductie
Maar wat is metadata eigenlijk? Metadata vormt de essentiële achtergrondinformatie die de organisatie, classificatie en begrip van gegevens en data mogelijk maakt. We vergelijken het met het etiket op een soepblik in de supermarkt: Net zoals het etiket cruciale informatie bevat over de ingrediënten, voedingswaarden en bereidingswijze van de soep, biedt metadata context en details over digitale gegevens.
Metadata geeft antwoord op de vragen wie, wat, waar, wanneer, waarom en hoe. Dit zijn bijvoorbeeld vragen over wie de data provider en steward zijn, wat de data betekent, wie mag de data inzien, waar is de data opgeslagen, en hoe je aan de specifieke data kan komen. Daarnaast bevat het normaliter informatie over de creatiedatum, bestandsformaat, locatie, en andere relevante kenmerken die essentieel zijn voor het begrijpen en beheren van de gegevens. Daartoe behoort ook verder ook de data lineage, oftewel, het pad van de gegevensbron naar de huidige locatie en de wijzigingen die daartussen zijn aangebracht (Steenbeek 2022).
Terwijl het soepetiket de consument helpt bij het maken van een weloverwogen keuze, stelt metadata gebruikers, systemen en software in staat om effectief te navigeren door en gebruik te maken van digitale informatie. Zo vormt metadata de sleutel tot een georganiseerde, efficiënte en begrijpelijke digitale omgeving.
Metadata vormt samen met data en de infrastructuur de ingrediënten die nodig zijn om de data en gegevens vindbaar, toegankelijk, uitwisselbaar en herbruikbaar te maken. Het is daarmee onlosmakelijk verbonden aan het FAIR-principe (Chapter 3).
2.2 Standaarden
Gelukkig hoeft niet elk soepmerk in de winkel het etiket opnieuw uit te vinden. Wetten en regels zorgen ervoor dat informatie verplicht gedeeld moet worden op het etiket. In de wereld van het metadata is dat niet anders.
Standaarden spelen een belangrijke rol bij het ondersteunen en bevorderen van het maken en gebruiken van metadata. Geteste en breed gedragen standaarden bevorderen het juiste gebruik van metadata en zijn noodzakelijk om deze informatie ook uitwisselbaar te maken.
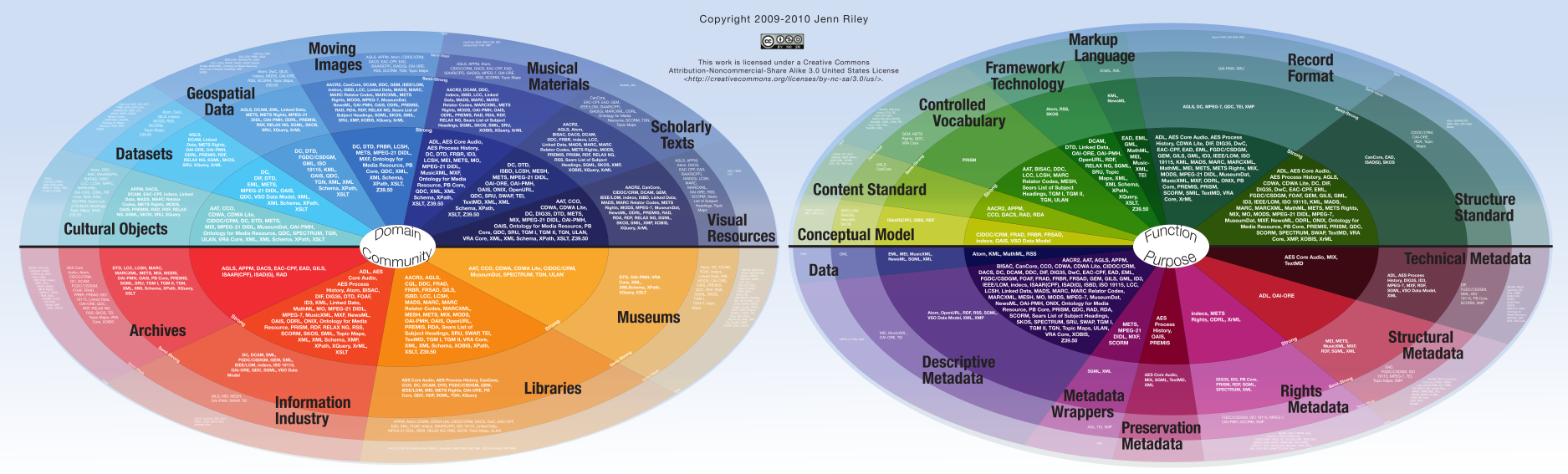 Figuur 2.1: Een visueel overzicht van het metadatalandschap door Jenn Riley (2020). Dit is een aangepaste versie. Klik hier voor de oorspronkelijke versie met uitleg, gepubliceerd onder de CC BY-NC-SA 3.0 US Deed Attribution-NonCommercial-ShareAlike 3.0 United States.
Figuur 2.1: Een visueel overzicht van het metadatalandschap door Jenn Riley (2020). Dit is een aangepaste versie. Klik hier voor de oorspronkelijke versie met uitleg, gepubliceerd onder de CC BY-NC-SA 3.0 US Deed Attribution-NonCommercial-ShareAlike 3.0 United States.
Het metadata landschap is wel flink versnipperd. Elk domein heeft zijn eigen metadata standaard. Dit is ook wel begrijpelijk, standaarden zijn makkelijker te ontwikkelen en toe te passen als ze goed aansluiten bij de thematische en technische kenmerken van de data die in dat domein gangbaar zijn.
Twee nuttige informatiebronnen over metadata en metadata standaarden zijn het Digital Curation Centre (DCC) en de Research Data Alliance (RDA). Het DCC is een toonaangevend expertisecentrum op het gebied van digitale informatie curatie. Op de DCC website kun je onder meer naar metadata standaarden zoeken gebaseerd op de discipline/domein, type repository or type data (Figuur 2.2).
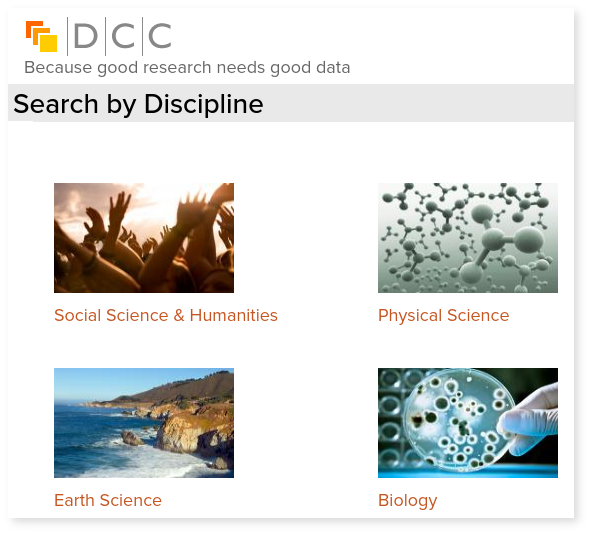 Figuur 2.2: Zoeken naar metadata schemas per (onderzoeks)domein op de DCC website.
Figuur 2.2: Zoeken naar metadata schemas per (onderzoeks)domein op de DCC website.
Het RDA ondersteund onder andere de Metadata standaarden catalogus. Dit is een door de internationale academische gemeenschap gedreven open lijst van metadatastandaarden specifiek gericht op onderzoeksgegevens. Ook hier kun je zoeken op onderwerp. Daarnaast bieden ook een overzicht van metadata gerelateerde offline en online tools, en een overzicht van schema’s om verschillende metadata standaarden aan elkaar te koppelen. Vooral als je in een multidisciplinair project actief bent waarin verschillende domeinen samenkomen is het waard om hier eens naar te kijken.
2.3 Metadata niveaus
Het opdelen van metadata in drie verschillende niveaus helpt bij het bespreekbaar maken van metadata. ‘Gegevens over gegevens’ kan op projectniveau, datasetniveau en attribuutspecifiek niveau worden bestempeld.
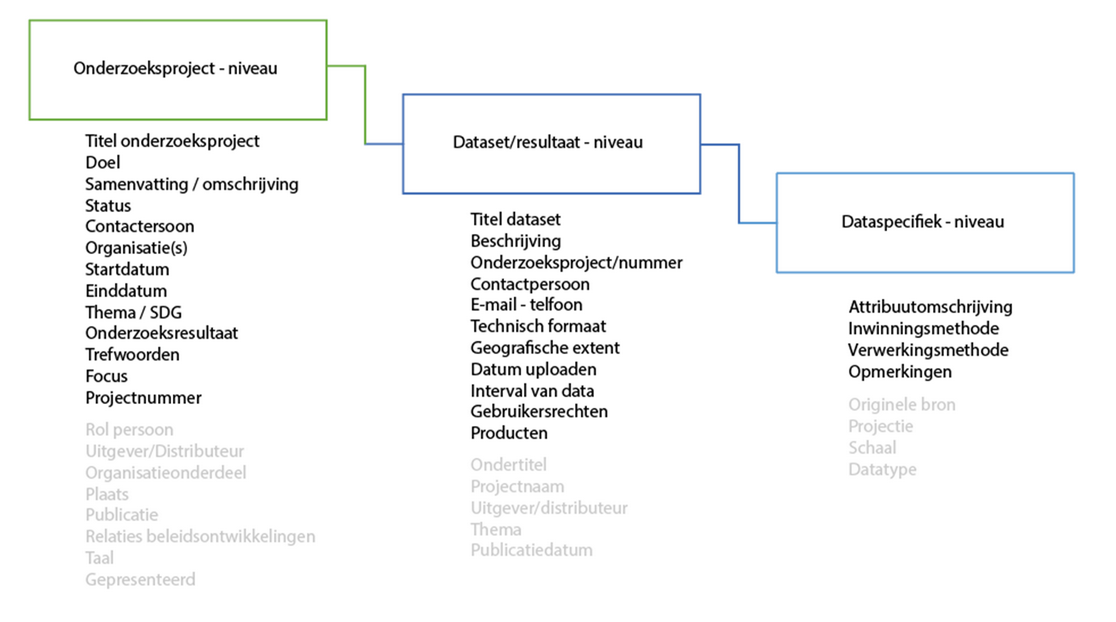 Figuur 2.3: Drie organisatorische niveaus waarop je data kunt beschrijven. Bron: Acceptatieformulier, NPPO (metadatamodel).
Figuur 2.3: Drie organisatorische niveaus waarop je data kunt beschrijven. Bron: Acceptatieformulier, NPPO (metadatamodel).
2.3.1 Projectniveau
Op het hoogste niveau bevinden zich projectniveau metadata. Deze informatie biedt een overzicht van het gehele project, inclusief het doel, de betrokken partijen, de tijdlijn en de algehele structuur van het project. Het helpt bij het begrijpen van de bredere context van de data en vergemakkelijkt samenwerking tussen verschillende teams die bij het project betrokken zijn. Projectniveau metadata is belangrijk bij het vaststellen van het kader waarbinnen data worden verzameld, verwerkt en gebruikt.
2.3.2 Datasetniveau
Hieronder valt metadata over datasets. Dit is data die van belang is bij het waarderen van een dataset. Dus metadata die helpt bij de keuze of dat een dataset wel of niet bruikbaar is voor een vraagstuk. De metadata van dit niveau beschrijft onder andere hoe de data binnen een specifieke dataset is gestructureerd, de tijdseenheid, de bron van de data en eventuele transformaties die zijn toegepast. Metadata op het niveau van de dataset helpt bij het begrijpen van de inhoud van een specifieke dataset, waardoor onderzoekers en analisten effectiever met de data kunnen werken.
2.3.3 Attribuutniveau
Dit niveau beschrijft de eigenschappen van individuele attributen of velden binnen een dataset, zoals de datatypes, eenheden en mogelijke waarden. Attribuutspecifieke metadata is van belang voor een nauwkeurige interpretatie van de data op gebruiks- en analyse niveau. Het helpt bij het vermijden van misinterpretaties en verkeerd gebruik van specifieke attributen, wat de nauwkeurigheid en betrouwbaarheid van analyses verbetert.
2.4 Metadata repository
Naast standaarden spelen metadata repositories, ook wel data catalogen genoemd, een belangrijke rol bij het ondersteunen en bevorderen van het gebruik van metadata. Waar standaarden normen vaststellen voor de structurering en beschrijving van metadata dienen metadata repositories als een georganiseerde opslagplaats voor digitale metadata informatie. Het doel daarbij is dat gebruikers informatie snel vinden en begrijpen.
Een metadata repository is een systeem om metadata op te slaan, te beheren en te bevragen. Maar een metadata repository slaat niet alleen metadata op, maar voegt daar vaak ook informatie aan toe over de (mogelijke) relaties tussen gerelateerde metadata types. Het doel is het helpen van onderzoekers en andere gebruikers om data te vinden, en om te bepalen of bepaalde data geschikt is voor een bepaald gebruik.
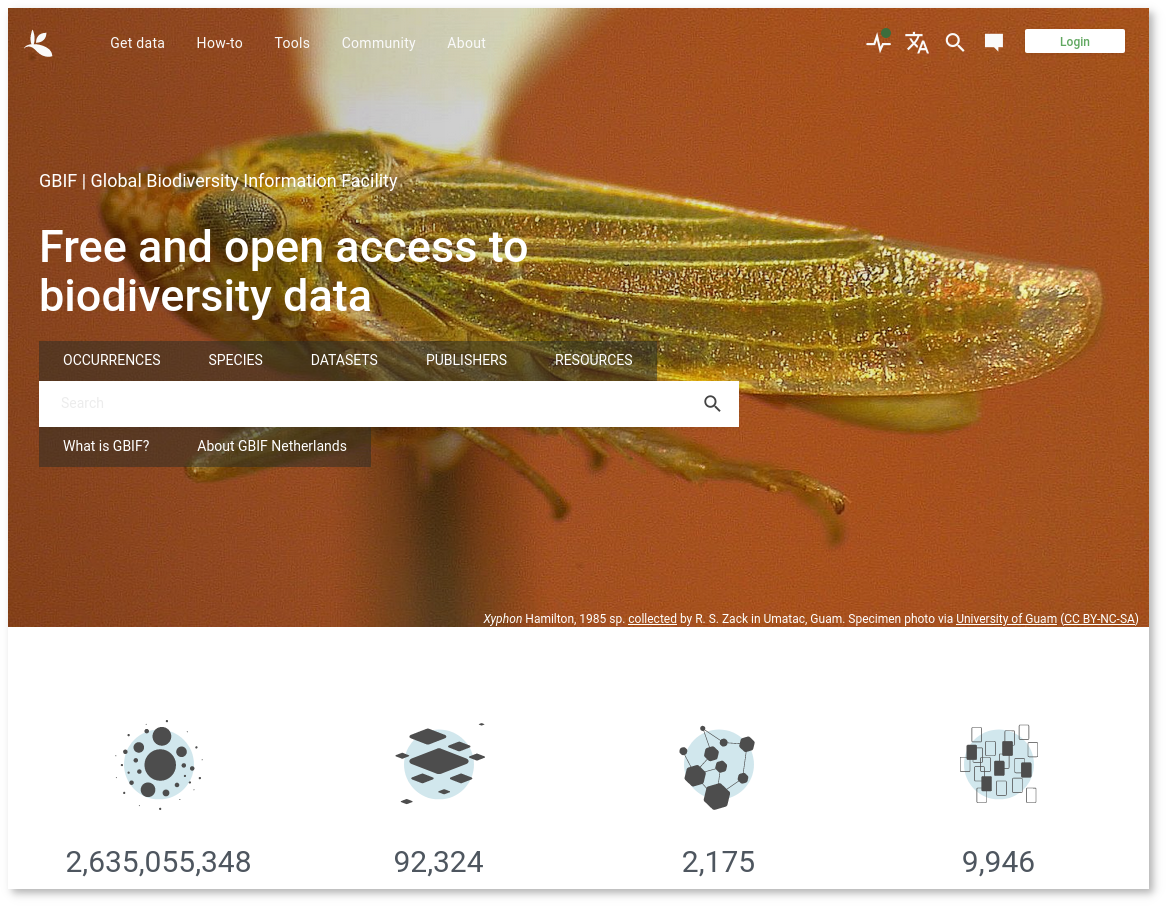 Figuur 2.4: De GBIF website is een goed voorbeeld van een metadata repository die gegevens vindbaar, toegankelijk, uitwisselbaar en herbruikbaar maakt. Onderdeel hiervan is de automatische toekenning van een DOI aan gegevens die worden gedownload. Dit maakt ook de data en informatie op basis van de GBIF-gegevens traceerbaar.
Figuur 2.4: De GBIF website is een goed voorbeeld van een metadata repository die gegevens vindbaar, toegankelijk, uitwisselbaar en herbruikbaar maakt. Onderdeel hiervan is de automatische toekenning van een DOI aan gegevens die worden gedownload. Dit maakt ook de data en informatie op basis van de GBIF-gegevens traceerbaar.
Een mooi voorbeeld van een data repository is gbif.org. GBIF is een netwerk dat open access biodiversiteitsdata van honderden instituten van over de hele wereld toegankelijk en vindbaar maakt (Figuur 2.4). Dit gebeurt door het gebruik van data standaarden zoals de Darwin Core standaard.
Een ander voorbeeld van een metadata repository is te vinden op re3data.org. Re3data is een wereldwijd register dat onderzoeksdatarepositories uit verschillende academische disciplines omvat.
2.5 Provider en gebruiker
Het werken met data levert een duidelijke tweedeling op. Je hebt de provider, die informatie verzameld, bewerkt en aanlevert. En je hebt de gebruiker, die vanuit een bepaalde rol nuttige informatie probeert op te halen. Beide partijen hebben hun wensen. De provider (dus degene die metadata definieert, toevoegt en onderhoud) kan tegen een aantal uitdagingen aanlopen. Deze kunnen in zes categorieën ingedeeld worden.
Het belang van bovenstaande uitdagingen hangt ook sterk samen met de wensen van de gebruiker. In elke situatie, denk bijvoorbeeld aan de vele verschillende projecten binnen de hogescholen, zijn er andere gebruikers die metadata nodig hebben om hun zoekvraag te kunnen beantwoorden.
Als provider kan het heel nuttig zijn om je data vanuit het perspectief van de gebruiker te bekijken, en je af te vragen wat die gebruiker zou willen weten om te besluiten of en hoe je de data kunt gebruiken. Denk daarbij aan mogelijke beperkingen of aannames waar de gebruiker zich van bewust moet zijn.
Probeer daarbij verder te kijken dan je eigen specifieke toepassing. Hoe zouden andere gebruikers je data nog meer kunnen gebruiken, en wat voor informatie over je data hebben ze daar voor nodig?
2.6 Doel & doelgroep
Het belang van het nauwkeurig definiëren van het doel en de doelgroep bij het metadateren van gegevens is cruciaal voor een effectief en efficiënt datamanagementproces. Het doel geeft richting aan de verzameling, opslag en analyse van gegevens, terwijl de doelgroep bepaalt wie de eindgebruikers zijn en welke informatie voor hen van waarde is. Door deze aspecten helder met elkaar te definiëren, kan metadata worden aangepast om rekening te houden met specifieke wensen, zoals de relevantie, nauwkeurigheid en noodzaak van bepaalde variabelen. Een zorgvuldige afstemming van doel en doelgroep zorgt ervoor dat de metadata aansluit bij de behoeften van gebruikers, waardoor de gegevens beter toegankelijk en begrijpelijk zijn. Dit verhoogt niet alleen de efficiëntie van het datagebruik binnen de organisatie, maar bevordert ook het delen van gegevens en de mogelijkheid om weloverwogen beslissingen te nemen op basis van nauwkeurige, relevante informatie.
2.7 DMP
Een data management plan (DMP) is van essentieel belang omdat het een gestructureerde aanpak biedt voor het beheren van onderzoeksgegevens gedurende de levenscyclus van een project. Enkele belangrijke kenmerken zijn dat het voorziet in een duidelijk kader voor het verzamelen, opslaan, beheren en delen van gegevens, waardoor de efficiëntie wordt verhoogd. Met het DMP leg je de standaarden en protocollen vast die helpen bij het borgen van de betrouwbaarheid van de verzamelde gegevens, en die herbruikbaarheid van onderzoeksgegevens bevorderen. Andere aspecten zijn risicobeheer en het voldoen aan wet- en regelgeving.
Door afspraken over metadata op te nemen in het DMP zorg je dat er contextuele informatie over de gegevens beschikbaar komt die de de interpretatie van gegevens makkelijker maakt, zelfs wanneer de oorspronkelijke onderzoekers niet beschikbaar zijn. Je borgt verder dat de verzamelde gegevens in een project ook na het einde van een project vindbaar en herbruikbaar zijn. Zie de twee links hieronder voor nuttige informatie over data management plannen.
Zoals je op deze sites kunt lezen zijn de FAIR principes zeer nuttig als leidraad bij de ontwikkeling van je DMP. Deze principes zijn het onderwerp van het volgende hoofdstuk.